AI governance map v.2.0
 www.nesta.org.uk/blog/ai-governance-map-v20/
www.nesta.org.uk/blog/ai-governance-map-v20/
www.nesta.org.uk/blog/ai-governance-map-v20/
www.nesta.org.uk/blog/ai-governance-map-v20/
A little over a year ago, Nesta launched a pilot database to provide a resource covering global activities related to the governance of artificial intelligence. Today, we are rebooting this effort with an updated website and an expanded database. In this post, we offer a few reflections on the ways in which discussions about AI governance have developed over the past year, and where they might go next.
Click here to see the map and database

In 2019 the hype around all things AI continued to grow. This was perhaps best captured by a meme for the occasion of Facebook’s controversial 10-year challenge - which was accused of being a poorly masked attempt at feeding facial recognition algorithms with valuable data. The meme in question mocked the fact that during the decade between 2009 and 2019, we had witnessed the wholesale rebranding of familiar statistical and computational tools as AI and machine learning. Although this is an exaggeration, the point may highlight the ways in which discussions about AI and machine learning are ultimately about the governance of digital technology more broadly, as data driven and algorithmic processes permeate all aspects of our lives. Throughout 2019, we continued to mostly subsume all that under the labels ‘AI’ and ‘machine learning’, but going ahead, it might prove increasingly unhelpful.
This was also aptly demonstrated by the inquiry of the New York City Automated Decision Systems Task Force into the city’s use of algorithms. The effort was regarded as a unique opportunity to bring transparency and accountability into the public use of algorithms, but it is now widely recognised as a failure. The task force could not uncover how automated systems are actually used and could therefore not advance substantial recommendations on their regulation. Nevertheless, the findings helped reinforce that automated systems do not need to be sophisticated or based on state-of-the-art technologies to have far reaching effects and potentially negative consequences.

To some extent, the task force’s disappointing outcome was to be expected, given that it had to operate with voluntary disclosures about how different city services rely on automated decision systems; thus it lacked any legal powers to gain meaningful insight. This is something Nesta identified as critical in our proposals for a Machine Intelligence Commission back in early 2016 before the creation of the Centre for Data Ethics and Innovation in the UK. Instead, the big discussions around the governance of AI in 2019 predominantly revolved around the role and scope of ethics.
Throughout the year, organisations of various types and sizes have continued to produce ethics guidelines, which now number over 100, and many have established ethics advisory boards. In order to create some clarity in this crowded space, multiple attempts have emerged that seek to catalog and analyse (Berkman Klein Center project; ETH Zurich project) the norms that are being put forward. While there is an emerging consensus around certain high-level principles that should underpin AI development, such as transparency, fairness and privacy, there is much less agreement about how these principles should be interpreted and operationalised in practice. In addition, concerns have been raised that the principle-based approach may be largely unsuited to AI governance.

Ethics, as the predominant mechanism of AI governance, has itself been profoundly challenged. Amid a wave of controversy, Google dismantled its ethics advisory board in April 2019, the European Union’s High-Level Expert Group on AI came under heavy criticism for the dominance of industry voices, the crowding out of civil society and downright ethics-washing, and revelations of the undue influence of Silicon Valley interests on the global AI ethics discourse shook the community. However, it would be a mistake to conclude that ethical reflection is superfluous. There is a lot that ethicists can contribute to teasing out the various ways in which high-level norms may be interpreted and implemented in computer code development or organisational processes. Yet, in the absence of regulation or practical mechanisms for the enforcement of principles, ethical codes inevitably play little role in shaping behaviour or incentives. Ethical guidelines can often feel like tweaking at the surface of more profound issues that exist at the level of business models and incentive structures.
In response to growing concerns about the societal impacts of their products and services, repeated record-breaking fines by authorities, waves of employee dissatisfaction and ongoing investigations in both Europe and the US, some of the largest technology companies have started calling on governments to create straightforward and binding regulations (Guardian; BBC; Techspot; Engadget). A patchwork of regulations or uncertainty about the rules that might apply are clearly undesirable for businesses, and there may even be a certain level of recognition on the side of tech companies that their products may have harmful societal consequences. However, these calls for regulation have been accompanied by increased lobbying activity and there are concerns that companies might capture the public and regulatory discussion and direct them away from the deeper structural issues at play.
In the United States, discussions about regulation are caught in a tension between the federal and the state level. The Office of Management and Budget released the first-year action plan of the Federal Data Strategy, which lays out the ways in which US agencies should manage and protect their data assets. While the White House appears to be pursuing a largely laissez-faire approach to AI regulation, even urging other parts of the world to do the same, individual states are leading the effort to regulate AI-based technologies in various domains. Privacy and data protection continue to be the primary areas of interest, but facial recognition and deepfakes have perhaps been the most dominant themes in 2019 with several bills and concrete pieces of legislation attempting to curb their use. In May, San Francisco became the first US city to ban public use of facial recognition, and a number of cities in California and Massachusetts followed suit (see map of facial recognition laws in the US).

Amid concerns related to the potential impact of deepfakes on the 2020 US elections, lawmakers in several US states, and also at the federal level have put forward legislative initiatives. A veritable arms race has developed with tech companies partnering with academic institutions to develop digital forensics tools to detect and prevent the spread of deepfakes. However, according to a recent analysis, current efforts are unlikely to offer sufficient safeguards against interference with the 2020 US elections.
Europe on the other hand seems to be intent on moving quickly. A recently leaked document about the Commission’s highly anticipated AI legislative agenda provides an insight into the range of issues that need to be resolved for effective legislation to be possible. Although the report briefly mentions the possibility of a temporary ban on facial recognition - which received considerable media attention but has already been dismissed as a policy option - the overall takeaway from the document is perhaps a recognition of the fact that regulating AI-based technologies is likely going to be a lengthy, iterative, and highly complex undertaking - despite initial rhetoric about regulating AI in the first 100 days of the new Commission. The white paper highlights several key inadequacies of the existing regulatory landscape, which include limitations of the current fundamental rights framework, lack of clarity with regard to chains of accountability, and difficulties around enforcement due to the lack of transparency of algorithmic systems.
The Council of Europe also issued a number of important documents on artificial intelligence and the protection of human rights and dignity. Unboxing AI offers practical recommendations for mitigating and preventing the harmful consequences of AI, while another set of guidelines focused especially on AI and data protection. In addition, the Committee of Ministers signed a declaration on the manipulative capabilities of algorithmic processes, drawing attention to the harms of predictive systems and automated decision-making, recognising the limitations of data protection frameworks to guard against the risk of manipulation. While these documents and commitments are not legally binding they provide important interpretative frameworks and confirm the fundamental role of human rights with regard to AI.

Policy activities have also been developing in individual Member States. A number of countries joined the club of nations with a dedicated AI strategy, including Portugal, Estonia, Serbia, Lithuania, Switzerland, Malta and Norway. The German Data Ethics Commission put forward suggestions for the horizontal regulation of algorithmic systems across the EU, and the UK Government published a guide to using AI in the public sector, draft recommendations for AI procurement, as well as a white paper on tackling online harms.
China’s National New Generation Artificial Intelligence Governance Expert Committee issued a set of principles for responsible AI, and the Beijing Academy of Artificial Intelligence released its principles as well. While both documents emphasise privacy and the protection of rights, reports and leaked documents have detailed how China uses advanced facial recognition and other AI tools to suppress and control members of the Uighur minority.
The Cabinet Office of Japan released a document entitled Social Principles of Human-centric AI, which describes seven overarching principles for AI development and implementation on the path towards the country’s vision of Society 5.0.
Singapore, which occupies the first spot in various measures of AI readiness has released updates to its Model AI Governance Framework, which offers voluntary guidance to the private sector on addressing ethical and accountability issues in AI systems. In addition, Singapore also operates a Data Regulatory Sandbox, allowing for the safe piloting of new uses of data for public benefit.
On the international stage, the OECD put forward a set of recommendations for AI, which strongly influenced the AI Principles adopted by the G20 countries. In addition the World Economic Forum released a general framework for crafting national AI strategies.
Reflecting on where we are now, it seems clear that existing mechanisms, such as competition and data protection law, are ill-equipped to address all the challenges that the pervasive use of algorithmic systems presents. The US Federal Trade Commission’s record $5 billion fine for Facebook left the company unscathed and even if we had perfect data protection systems in place, we would still see wide ranging detrimental effects of AI-based technology.
Overall, 2019 may be remembered as the year when the familiar imperative to ‘move fast and break things’ finally lost its appeal and societal reflection started to shift to a deeper level of questioning about how technology can serve the public good. Going ahead, facial recognition and deepfakes technology will continue to dominate the regulatory discussion, but there needs be a strengthened emphasis on aspects that have so far been neglected, such as directly addressing the extractive business models of large technology companies. Talk of commitment to human rights must translate into action in order to avoid the use of AI-tools for such controversial goals as lie detection at border crossings. Beyond data protection, we need to recognise the role of privately owned and operated optimisation infrastructures, and move from a focus on technology adoption to questioning the desirability and appropriateness of AI-based solutions to various problems. These technologies are already pervasive and their scope to shape and orchestrate individual and societal action is only likely to grow over the coming period. The choices we make today with regard to norms, standards and laws will provide the basic architecture for future innovation. Therefore, it is of crucial importance that we get it right.
We thank all those who offered valuable comments, suggestions and additions on the prototype of our database. Our aim is to create an informal network of contributors to help maintain this resource and keep it up to date. Please, get in touch if you are interested in joining us!







{kind=link}
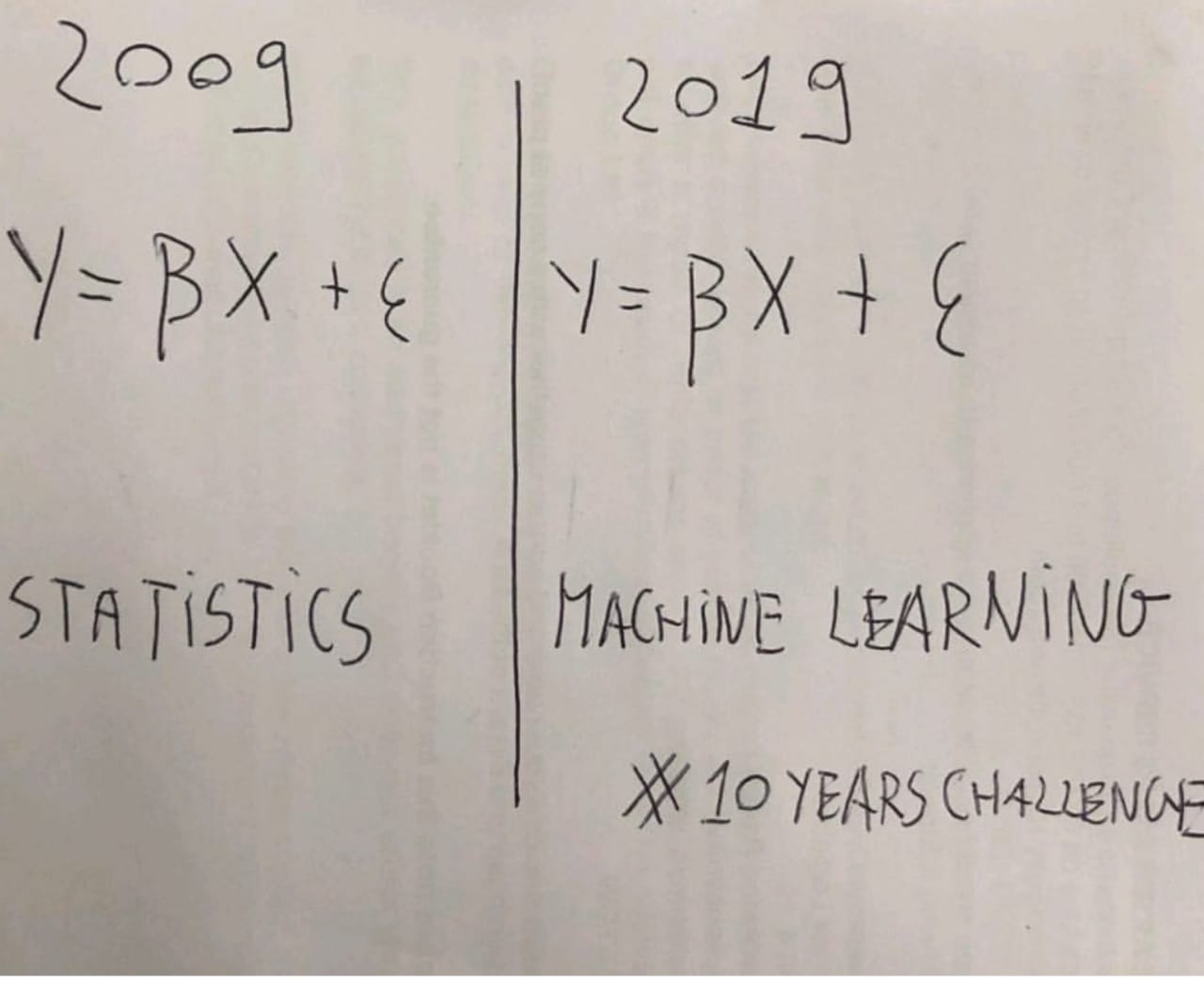{kind=link}